A few months ago I was sitting in a client call with a hospital CTO who had just approved a budget to "deploy an LLM for everything." ICD-10 coding, PHI de-identification, discharge summaries, triage notes — all of it through one big decoder model. I asked him one question: "What's your inference budget per request?" He went quiet. That silence told me everything I needed to know about where this was going.
We ended up redesigning the whole stack. Not because LLMs are bad — they're remarkable — but because architecture is destiny. The wrong transformer family for a task doesn't just waste money; it breaks regulatory requirements, tanks calibration, and in healthcare, can genuinely harm patients through hallucinated drug names and missed PHI boundaries.
This is the reference I wish I'd had earlier in my career. It covers all three transformer families — encoders, encoder-decoders, and decoder-only LLMs — with concrete reasoning for when each wins in HealthIT and Finance. I'll skip the benchmark tables (those age in weeks) and focus on architectural inductive bias: the structural reasons why one family fits a task better than another, regardless of parameter count.

TL;DR (For When Your Standup Starts in 3 Minutes)
- Encoders (BERT/RoBERTa/DeBERTa-v3/ModernBERT, ClinicalBERT, FinBERT): fast, cheap, calibrated. Default for classification, NER, PHI removal, embeddings. They understand — but cannot generate.
- Encoder-decoders (T5/FLAN-T5/BART/PEGASUS/ClinicalT5): cross-attention keeps generation faithful to source. Best for summarization, translation, structured rewriting. Hallucinate less than LLMs on bounded tasks.
- Decoder-only LLMs (Llama 3, Qwen2.5/3, GPT-4, Claude, Med-PaLM 2, BloombergGPT): open-ended reasoning, agents, tool calls, zero-shot generalization. Powerful but expensive, calibration is a problem, and compliance overhead is real.
- The 2026 enterprise pattern is hybrid, not "one big LLM." Encoder at the edge for cheap classification/NER → seq2seq or decoder for controlled generation → encoder verifier to catch hallucinations and PHI. Each layer chosen for its inductive bias, not hype.
- Decision rule: pick the smallest architecture whose bias already matches the task, then escalate. Using a 70B decoder for binary intent classification is ~100× over-spend. Using BERT for ICD-10 with 70K labels and 10 examples per code is statistical malpractice.
The Three Families: A 60-Second Primer
Think of the original 2017 Transformer (Vaswani et al.) as a restaurant kitchen with three stations: a prep station that reads the entire recipe at once (bidirectional encoder self-attention), a plating station that builds the dish one component at a time only looking back at what's already plated (causal decoder self-attention), and a pass-through window where the plating station can glance back at the prep station's notes at any moment (cross-attention). Every model since 2017 is just a decision about which stations to keep open.
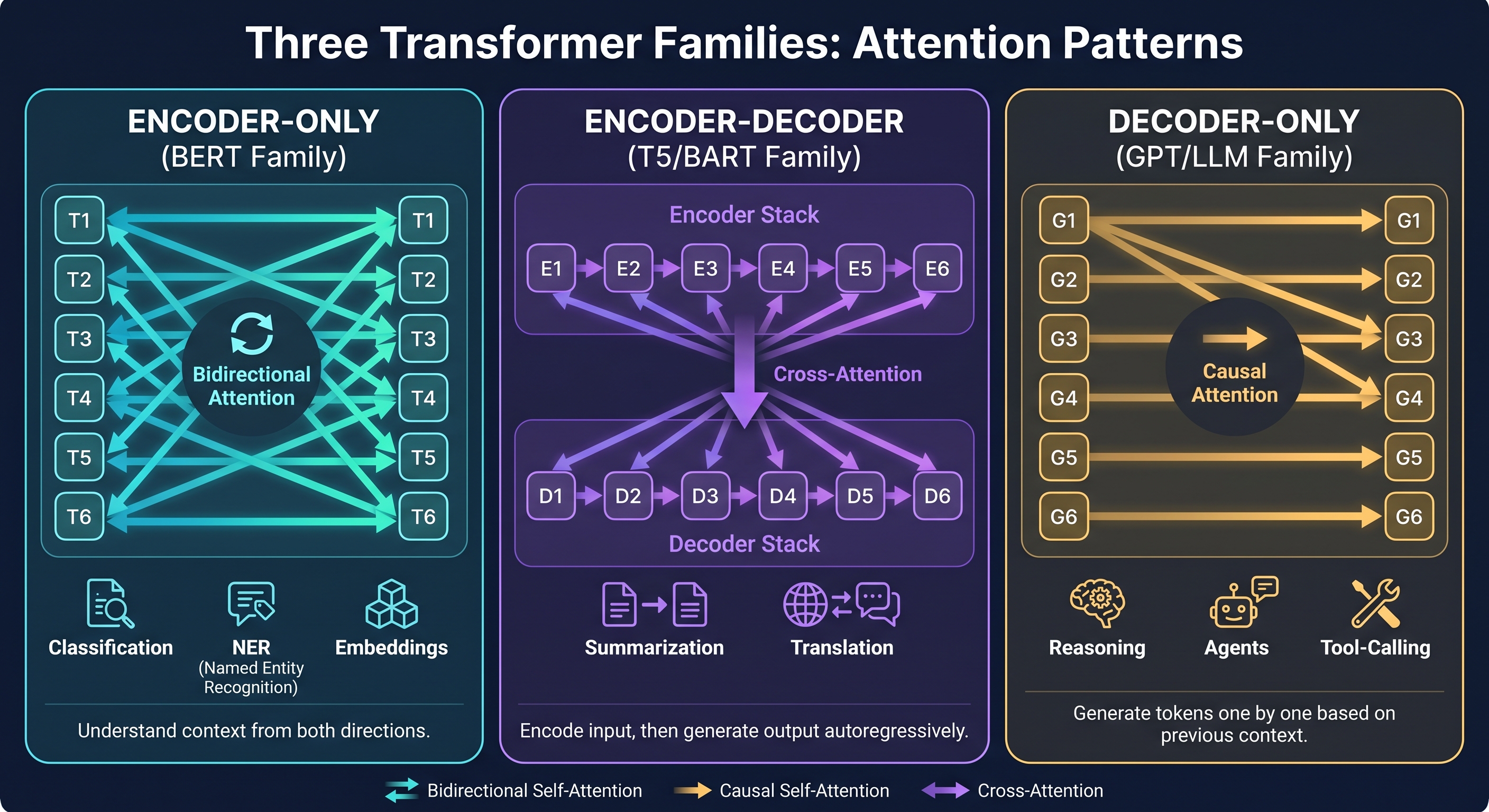
Encoder-Only: The Understanding Specialists
BERT (Devlin et al., 2018) keeps only the prep station. Every token sees every other token simultaneously — this is bidirectional attention, and it's the key insight. If you want to classify a clinical note, you need to understand "the patient denied chest pain" in full context: "denied" completely changes the clinical meaning of "chest pain." An encoder sees both words at once and integrates them. A decoder, reading left to right, sees "the patient denied" and only then encounters "chest pain" — by which point the representation has already been built with the wrong frame.
The Masked Language Modeling objective (predict masked tokens from both directions) forces the model to build exactly these rich bidirectional representations. Result: encoders are unbeatable for understanding tasks — classification, NER, span extraction, embeddings.
2026 state of the art:
- DeBERTa-v3 (He et al.): disentangled content/position attention + ELECTRA-style pretraining. Strongest general encoder for NLU.
- ModernBERT (Warner et al., Dec 2024): RoPE, GeGLU, FlashAttention, 8,192-token native context, alternating local/global attention. Proves the encoder paradigm isn't obsolete — it just stopped being modernized.
- Clinical ModernBERT / BioClinical ModernBERT (2025): ModernBERT adapted to PubMed + MIMIC-IV. 8K context means whole discharge summaries in one pass — no chunking artifacts.
- FinBERT (Araci): BERT continued-pretrained on financial corpora. Industry standard for earnings-call sentiment as a calibrated 3-way classifier.
Encoder-Decoder: The Faithful Translators
T5 (Raffel et al.), BART (Lewis et al.), and PEGASUS (Zhang et al.) keep all three stations. The bidirectional encoder reads the full input and builds a rich representation; the causal decoder generates output while attending to that encoder representation at every single step via cross-attention.
This cross-attention is crucial. At every generation step, the decoder can ask: "does what I'm about to write match what the source actually said?" It's the architectural equivalent of a court interpreter who keeps glancing at the original transcript before speaking each word. This is why seq2seq models hallucinate less than decoder-only LLMs on summarization and translation — the conditioning mechanism is structural, not just a prompt instruction.
PEGASUS's Gap-Sentence Generation pretraining (mask entire salient sentences, force the decoder to regenerate them) is a near-perfect proxy for abstractive summarization. The model literally learns to summarize during pretraining, not just during fine-tuning. For clinical discharge summary generation or financial earnings summaries, this matters enormously.
Decoder-Only LLMs: The Generalists
GPT-family models keep only the plating station — causal, left-to-right attention. One token at a time, each attending only to what came before. The training objective (predict next token) is the simplest conceivable self-supervised task, but at scale it produces something remarkable: a model that has essentially memorized the conditional distribution of human language, and can therefore generalize to almost any task via instruction following and in-context examples.
The tradeoffs are structural, not incidental. Causal masking means every token representation is built without seeing what comes to its right — which is fine for generation but suboptimal for understanding. The "reversal curse" (GPT-style models fail at logical relations that require symmetric reasoning) is a direct consequence (vs. BERT's symmetric handling). And because the model produces probability distributions over vocabulary tokens — not probability distributions over classes — the output is not naturally calibrated for risk-threshold decisions.
graph LR
subgraph Encoder["ENCODER (Bidirectional)"]
direction LR
T1["Token 1"] <--> T2["Token 2"]
T2 <--> T3["Token 3"]
T1 <--> T3
end
subgraph Decoder["DECODER (Causal)"]
direction LR
G1["Gen 1"] --> G2["Gen 2"]
G2 --> G3["Gen 3"]
end
subgraph CrossAttn["CROSS-ATTENTION (Seq2Seq bridge)"]
Encoder --> G1
Encoder --> G2
Encoder --> G3
end
style Encoder fill:#0e4a6e,color:#7dd3fc
style Decoder fill:#4a1e6e,color:#c4b5fd
style CrossAttn fill:#1e3a1e,color:#86efacThe Swiss Army Knife Mistake
Here's the analogy I use with clients. Imagine you're doing surgery. You could use a Swiss Army knife — it has a blade, scissors, even a tiny saw. But you wouldn't, because a surgical scalpel is specifically designed for precision incision, and using the wrong tool doesn't just add friction — it causes harm.
The same logic applies to transformer architectures. Using a 70B decoder-only LLM for binary intent classification is like using a Swiss Army knife for surgery: technically possible, absurdly expensive, introduces unnecessary failure modes (hallucinated outputs instead of clean class probabilities), and will fail your compliance audit when the regulator asks "show me your calibration curve."
Conversely, using a BERT-family encoder for ICD-10 coding across all 70,000 codes with sparse training data is like trying to perform open-heart surgery with a scalpel alone — the right precision instrument, completely wrong for the scale of the task. You need something with more generative reach.
Architecture is about matching the tool to the job. Let's build that matching framework.
The Architect's Decision Framework
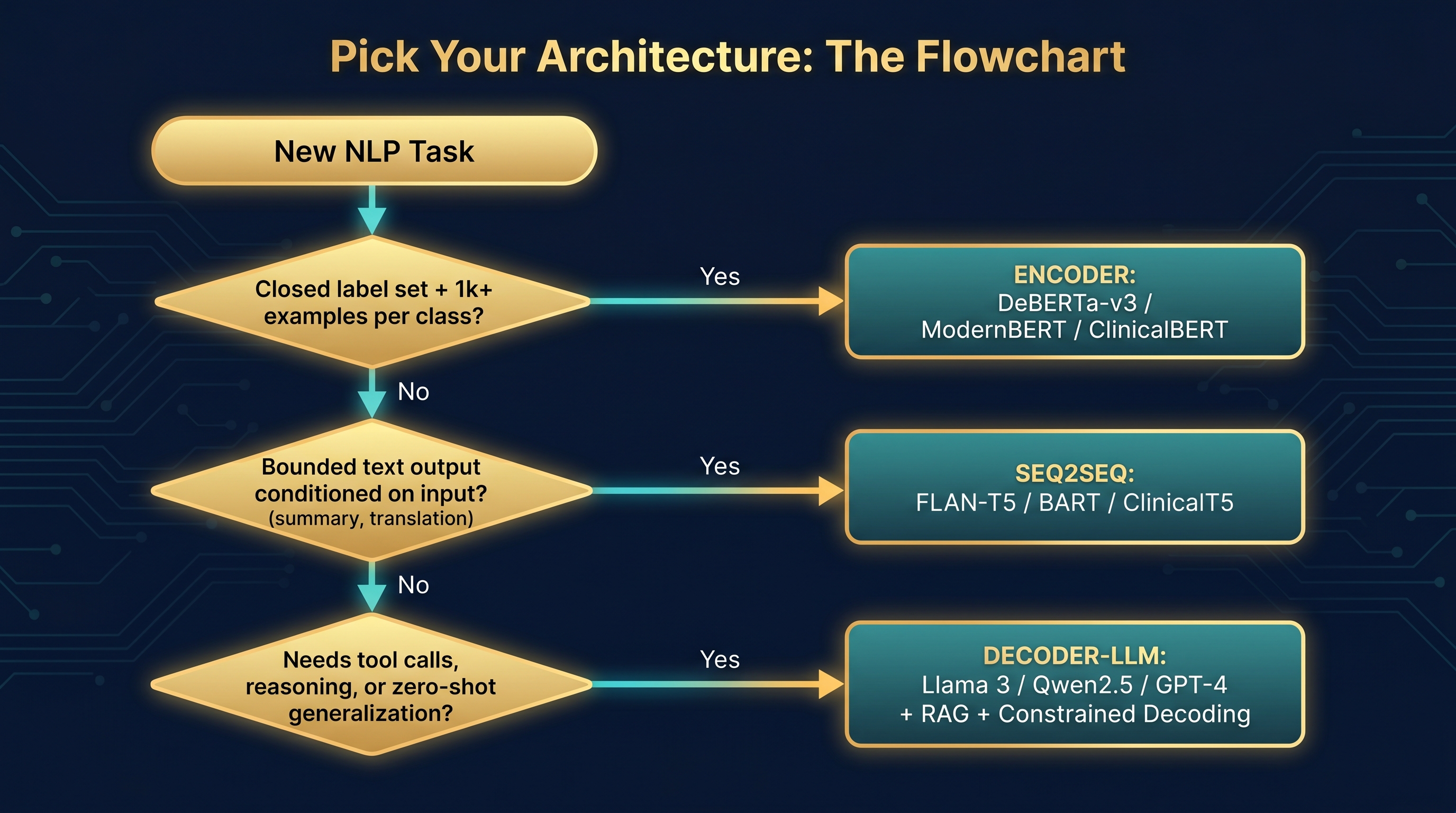
Three questions. In order. Don't skip ahead.
flowchart TD
A([New NLP Task]) --> Q1{Closed label set +
≥1k examples/class?}
Q1 -->|YES| E["🔵 ENCODER
DeBERTa-v3 / ModernBERT
ClinicalBERT / FinBERT
+ classification head"]
Q1 -->|NO| Q2{Bounded text output
conditioned on input?
summary / translation /
structured rewrite}
Q2 -->|YES| S["🟣 SEQ2SEQ
FLAN-T5 / BART / PEGASUS
ClinicalT5 / mT5
+ constrained decode"]
Q2 -->|NO| Q3{Tool calls / agents
open reasoning
zero-shot generalization?}
Q3 -->|YES| D["🟡 DECODER-LLM
Llama 3 / Qwen2.5 / GPT-4
+ RAG + constrained decode
+ encoder verifier"]
Q3 -->|NO| R[Re-scope the task.
You probably have an
encoder problem.]
style E fill:#0e4a6e,color:#7dd3fc
style S fill:#4a1e6e,color:#c4b5fd
style D fill:#4a3500,color:#fbbf24
style R fill:#3d1a1a,color:#fca5a5Then, regardless of family:
- ≥10B in-domain tokens + domain-general underperforms → domain pretraining (BioBERT, ClinicalBERT pattern)
- 100K–10B in-domain tokens → LoRA/QLoRA fine-tuning
- <100K tokens → prompt engineering + RAG
- Always: evaluate calibration (reliability diagrams + Brier score), not just accuracy
HealthIT Deep Dives
Clinical NER and PHI De-identification
This is the encoder's home territory. Clinical NER — extracting medications, conditions, dosages, lab values from discharge notes — requires per-token labels that depend heavily on both left and right context. "The patient was prescribed metformin" and "the patient was not prescribed metformin" differ by one word to the left of the entity, which only bidirectional attention catches cleanly.
PHI de-identification is even more unforgiving. HIPAA Safe Harbor requires deterministic, auditable token boundaries. An encoder fine-tuned on i2b2 2014 data will give you >99% F1 with precise start/end character offsets. A decoder-LLM will give you approximate spans wrapped in prose like "the patient's name appears to be..." — which is legally useless and an audit disaster.
My recommendation: Clinical ModernBERT or BioClinical ModernBERT as your 2026 backbone. The 8,192-token context means an entire discharge summary processes in one pass without the chunking artifacts that plagued earlier clinical BERT variants on long documents. Use a decoder-LLM only as a secondary verifier on flagged spans, never as the primary PHI detector.
ICD-10 Coding: The 70,000-Label Problem
This one breaks naive architectural intuitions. ICD-10 has ~70,000 codes. Naively you'd think: large closed label space → encoder wins. But this ignores the sparsity reality: most codes appear fewer than 10 times in any training set. A BERT classifier with 70K output heads and 10 positive examples per code is not a classification model — it's a statistics disaster.
The correct architecture is two-stage hybrid:
- Clinical ModernBERT multi-label classifier: short-list the top 50–100 candidate codes based on the learned representation. The encoder is good at this because the signal for "this is a metabolic disorder" is strong in the dense representation even without code-specific training data.
- Decoder-LLM with constrained decoding: select and rank from the candidate short-list against the clinical narrative. With only 50–100 candidates, the constrained decode space is manageable, and the LLM's reasoning ability handles the disambiguation.
Pure encoder fails on long-tail codes. Pure LLM is too expensive at 70K-way constrained decode without short-listing. The hybrid is the answer every time.
ESI Triage: Where I Actually Ran Into This
When I was working on our ESI (Emergency Severity Index) triage system with Qwen2.5 9B fine-tuning, the architectural question wasn't "LLM or encoder" — it was "what does the 9B decoder buy us over a fine-tuned ClinicalBERT?" The answer depends on what you care about.
A fine-tuned ClinicalBERT gives you: calibrated 5-class probabilities you can threshold, sub-10ms inference on CPU, and a clean audit trail (the linear head weights are interpretable). A fine-tuned Qwen2.5 9B gives you: free-text rationales alongside the classification, better handling of ambiguous triage notes where context across the full ED narrative matters, and better generalization to edge cases.
For clinical decision support, rationales are not a luxury — they're often the difference between a clinician trusting the system or ignoring it. But: you must evaluate calibration explicitly. Extract the class probabilities from the decoder (via constrained decoding into a fixed label set + log-prob renormalization), plot your reliability diagram, and validate on a held-out set before any deployment. A 9B model with poor calibration is worse than a 110M encoder with good calibration in a clinical setting where "90% confident" needs to mean something.
Discharge Summary Generation
Cross-attention is your friend here. A seq2seq model (ClinicalT5, FLAN-T5 fine-tuned on clinical data) that attends back to the source at every generation step will hallucinate fewer medications and dosages than a decoder-only LLM that's trying to generate the summary purely from its parametric memory plus a long context prompt.
Multiple papers on medical hallucination (2025 taxonomy, MedHallBench) confirm non-trivial extrinsic hallucination rates even in frontier models. A hallucinated drug dosage in a discharge summary is a patient safety issue. The cross-attention bias isn't just architecturally elegant — it's clinically safer at equivalent compute.
My hybrid faithfulness pipeline:
- Encoder-based extractive retrieval of the most clinically salient sentences from the note
- ClinicalT5 abstractive rewrite with copy bias
- NLI encoder (DeBERTa-v3 fine-tuned on NLI) checking that every generated sentence is entailed by the source
Decoder-LLMs come in only when you need cross-note synthesis (e.g., "summarize this patient's 5-year clinical history across 12 notes") where the raw reasoning capability matters more than single-note faithfulness.
Multilingual Clinical NLP: The UAE/Arabic Case
For our Arabic and Emirati dialect clinical work, the architecture stack becomes: Whisper-large-v3 (fine-tuned on dialectal medical audio) → mT5 or NLLB for English translation when needed → Clinical ModernBERT for NER → LLM for summarization. Each layer chosen on inductive bias.
mT5 beats decoder-only LLMs on translation faithfulness for tightly bounded clinical text. The cross-attention ensures every English output word is accounted for by the Arabic source. For dialectal Arabic where the decoder LLM may not have seen enough training data, the encoder-decoder's conditioning mechanism is a safety net. Decoder LLMs like Qwen2.5 (which has strong multilingual performance including Arabic) come in at the summarization and reasoning layer where their generative flexibility actually adds value.
Finance Deep Dives
FinBERT: The Right Tool, Done Right
FinBERT sentiment on earnings calls is the canonical "encoder wins" case. You have a closed 3-label space (positive/neutral/negative), abundant training data (Financial PhraseBank plus your own labeled corpus), well-defined domain vocabulary, and a downstream use case (trading signal generation) that requires calibrated probabilities — not prose rationales.
The signal pipeline looks like: earnings call transcript → FinBERT sentence-level 3-way classification → aggregated sentiment score with confidence intervals → threshold-based trading signal → backtest. The confidence intervals matter: a FinBERT output of 0.51/0.49/0.00 is a "weak positive" and should not drive the same position size as 0.95/0.04/0.01. This calibration is only possible with an encoder's clean softmax. A decoder-LLM that outputs "I'd call this slightly positive" gives you nothing to threshold.
BloombergGPT vs. FinGPT: The Build-vs-PEFT Lesson
BloombergGPT (Wu et al.) is a masterclass in what a financial powerhouse can do when cost is no object: 50B parameters, 363B finance tokens plus 345B general, trained from scratch. It beats general LLMs on finance-specific benchmarks. It also costs an amount most organizations should never consider spending.
FinGPT (Yang, Liu, Wang) demonstrates the practical alternative: LoRA fine-tuning on top of Llama. Same downstream performance on most tasks, 1–2 orders of magnitude cheaper. This is the "FinGPT lesson" and it applies equally in healthcare. Almost never train from scratch. Start from an open-weights frontier model (Llama 3, Qwen2.5) and PEFT. Reserve from-scratch for organizations with ≥100B proprietary tokens and unique safety requirements — which is Bloomberg and basically nobody else.
Open-Domain Q&A Over SEC EDGAR Filings
This is the canonical RAG case. "What were the three biggest risk factors disclosed across Amazon's last five 10-K filings?" cannot be answered by an encoder alone (no generation), a vanilla decoder alone (no reliable grounding in 500+ pages), or a seq2seq model alone (the output isn't bounded or strongly conditioned on a single input). You need the three-stage RAG pipeline:
- Hybrid retrieval: BM25 keyword match + dense embedding retrieval (FinBERT-tuned or BGE) + cross-encoder reranker (DeBERTa-v3 fine-tuned on relevance pairs)
- Generator: decoder-LLM (GPT-4 or Claude) with retrieved passages + citation-required prompt
- Verifier: NLI encoder checking every output claim against its cited passage
Note the encoders re-enter as both the retrieval layer and the verifier layer, even though the generator is a frontier decoder-LLM. This is the 2026 pattern: decoders generate, encoders govern.
Contract Clause Extraction
Standard contracts (NDAs, MSAs, SOWs with known clause taxonomy): DeBERTa-v3 fine-tuned on CUAD-style data — fast, cheap, calibrated, explainable. Novel contract types or ambiguous language: decoder-LLM with constrained JSON output, since the LLM's reasoning handles the ambiguity and the schema constraint keeps output machine-readable. This is a genuinely hybrid use case where the answer depends on the contract type distribution in your pipeline.
The Enterprise Hybrid Pipeline
After building production systems across healthcare and finance clients, I've converged on a pattern I call the "encoder sandwich": encoders at the edges, decoder in the middle, seq2seq when bounded generation is the task.
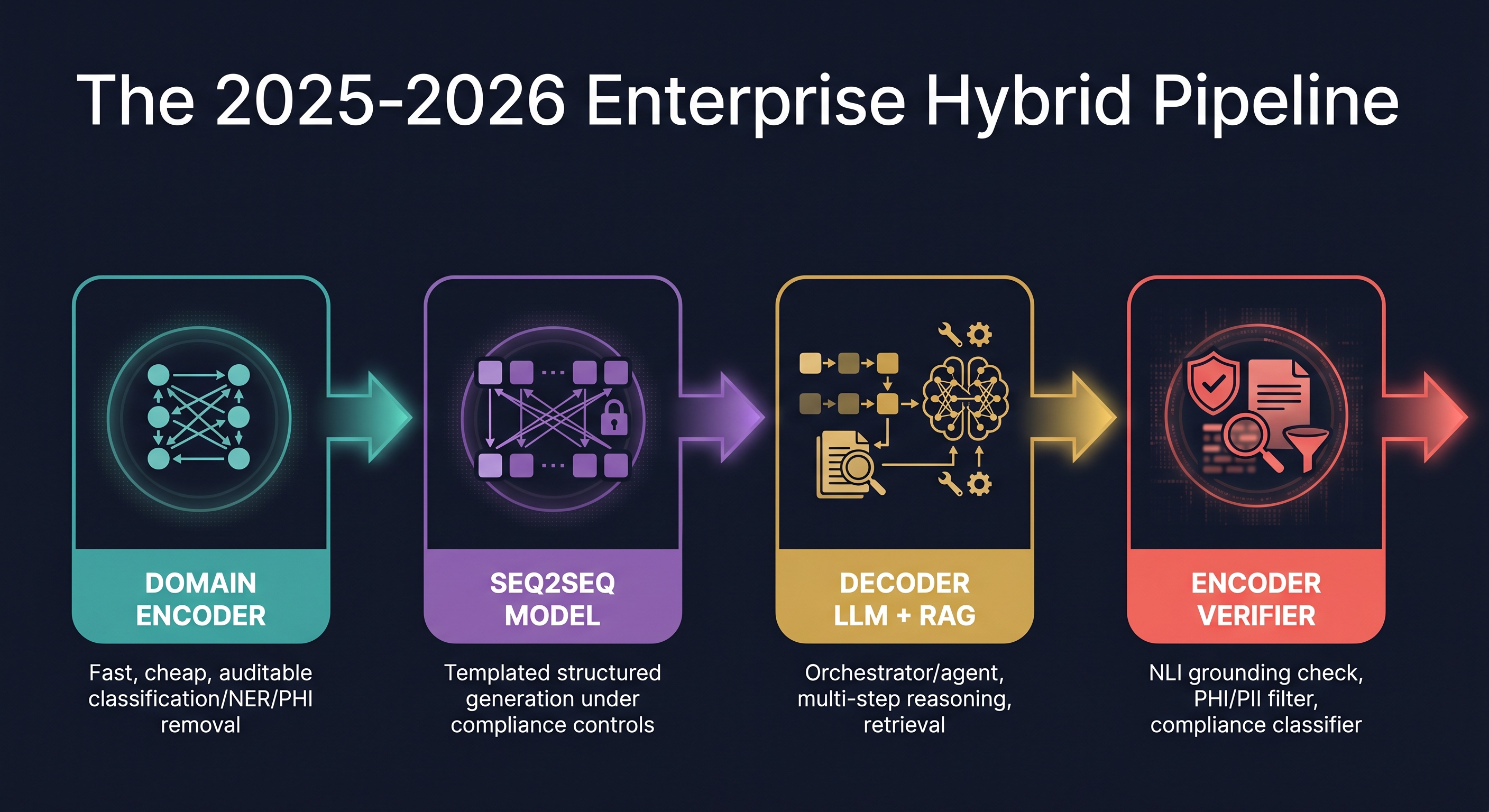
flowchart LR
Input([Raw Input
Text / Speech]) --> E1
subgraph Edge["Edge Layer (Encoder)"]
E1["Clinical ModernBERT
or FinBERT
• Intent classification
• PHI/PII detection
• Compliance flag
⚡ <10ms CPU"]
end
E1 -->|Clean, classified input| Core
subgraph Core["Core Layer (Seq2Seq or Decoder-LLM)"]
S2S["FLAN-T5 / ClinicalT5
Bounded generation tasks
• Summaries
• Translation
• Structured rewrites"]
LLM["Llama 3 / Qwen2.5
+ RAG + Tools
Open reasoning tasks
• Agents
• Multi-step QA
• ICD re-ranking"]
end
Core --> V1
subgraph Guard["Guard Layer (Encoder)"]
V1["DeBERTa-v3 NLI Verifier
• Hallucination detection
• PHI boundary check
• Compliance classifier
• Grounding score"]
end
V1 -->|Verified, safe output| Output([To User or
Downstream System])
style Edge fill:#0e3a5e,color:#7dd3fc
style Core fill:#2a1a4e,color:#c4b5fd
style Guard fill:#1a3a1a,color:#86efacThe key insight is that encoders re-enter as verifiers even when the primary generator is a frontier decoder-LLM. You've spent $0.01 on the LLM call; spending $0.0001 on an NLI encoder to verify grounding is free insurance. This asymmetry is why the hybrid pattern dominates: decoders give you capability, encoders give you governance.
Architecture × Domain Matrix
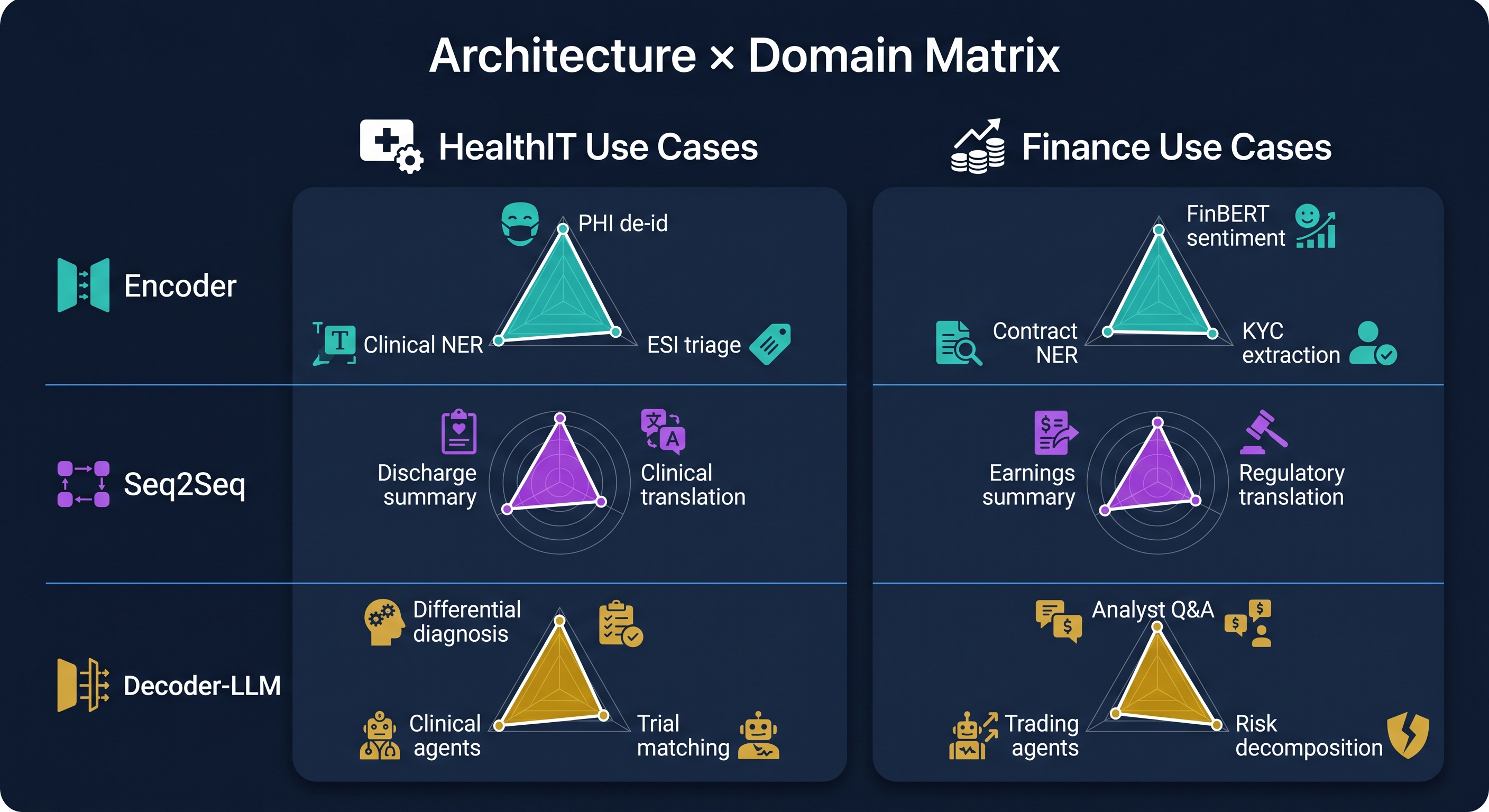
| Task | HealthIT Example | Finance Example | Winner |
|---|---|---|---|
| Token classification / NER | Clinical NER, PHI de-id | Ticker/company/amount NER | 🔵 Encoder |
| Text classification | ESI triage acuity (1–5) | Sentiment on earnings calls | 🔵 Encoder |
| Summarization | Discharge summary generation | Earnings call / 10-K MD&A | 🟣 Seq2Seq |
| Translation | Arabic ↔ English clinical notes | Multilingual regulatory filings | 🟣 Seq2Seq |
| Embeddings / retrieval | Patient cohort retrieval | SEC filing similar-deal search | 🔵 Encoder |
| Open-domain QA / RAG | Clinical guideline Q&A | Analyst Q&A over EDGAR | 🟡 Decoder + RAG |
| Multi-step reasoning | Differential diagnosis | Risk decomposition | 🟡 Decoder-LLM |
| Agentic / tool use | FHIR-calling clinical agent | Portfolio / trading agent | 🟡 Decoder-LLM |
| ICD-10 coding (70K labels) | Discharge coding | — | 🔵+🟡 Hybrid |
Where Encoders Still Beat LLMs in 2026
Let me be direct about this because the hype cycle has caused real damage. Despite frontier LLMs achieving remarkable things, encoders win — architecturally and economically — in these scenarios:
- High-throughput classification (>1K QPS on commodity hardware). A 110M-parameter encoder runs on CPU at <10ms per call. A 70B decoder cannot match this at any cost. For high-volume clinical document routing or real-time financial news triage, the economics are not close.
- Calibrated probabilities for risk thresholds. Softmax over a closed label set, fine-tuned with proper scoring rules, gives well-calibrated outputs. Decoder log-probs are not class probabilities and require extensive recalibration before use in any risk-threshold decision. Regulators asking "what does your model's 80% confidence actually mean" deserve a reliability diagram, not a shrug.
- PHI / PII de-identification. The deterministic, auditable token boundaries that HIPAA Safe Harbor requires. RoBERTa-large and DeBERTa-v3 on i2b2 2014 achieve >99% PHI accuracy with precise character offsets. Probabilistic generation from an LLM is an audit liability.
- Closed-label tasks with abundant data. 200 intent classes, 10K examples each — encoder fine-tuning dominates LLM prompting on both cost and quality. The encoder's inductive bias for understanding is exactly matched to this task.
- Embeddings for retrieval. Sentence-BERT, BGE, GTE, ModernBERT-based retrievers are the foundation of every production RAG system, including those whose generators are 405B-parameter LLMs. Encoders build the retrieval index that makes decoders useful.
- Edge and on-device deployment. ONNX-quantized encoders run on phones and embedded systems. For clinical dictation triage or offline document classification, the 8-billion-parameter club doesn't apply.
- Regulated environments requiring explainability. A linear classification head over a frozen encoder produces feature attributions (via integrated gradients, SHAP, or attention weights) that compliance teams can actually review. EU AI Act Article 13, HIPAA, and SR-11-7 all care about this.
A Note on Agentic AI: Not Solved, Design Accordingly
The Berkeley Function Calling Leaderboard (BFCL) results from 2025–2026 are humbling. Multi-turn agentic tool use — long-horizon reasoning, dynamic decision-making, memory across turns — is still an open problem even in frontier models. "The agent will handle it" is not an architectural design; it's a wish.
For HealthIT agents (FHIR-calling clinical decision support, trial matching à la TrialGPT) and Finance agents (portfolio management, regulatory reporting), design for graceful degradation:
- Cap ReAct loop depth (prevent infinite reasoning chains)
- JSON-Schema-constrain every tool argument (prevent hallucinated API calls)
- Log every (thought, action, observation) tuple for audit
- Human-in-the-loop gates for consequential actions (orders, prescriptions, trades above threshold)
- Fuzz-test tools against adversarial inputs including prompt-injection via retrieved content
The agent is not the decision-maker. The human is the decision-maker; the agent is a very capable research assistant with terrible self-awareness about what it doesn't know.
Architect's Playbook
Next 30 Days: Scoping a New Project
- Run the Section 4 flowchart before writing a single line of code
- HealthIT default backbone: Clinical ModernBERT or BioClinical ModernBERT; Finance default: FinBERT or DeBERTa-v3 continued-pretrained on financial text
- Summarization under hallucination constraints: FLAN-T5 / ClinicalT5 / BART before reaching for a 70B decoder
- Agentic/RAG work on-prem regulated: Qwen2.5/Qwen3 or Llama 3.x; cloud OK: GPT-4 / Claude
Next 90 Days: Productionizing
- Wrap every decoder-LLM output with encoder verifiers (NLI grounding, PHI/PII filter, compliance classifier)
- Use constrained decoding for any output consumed by another system (FHIR, JSON, SQL, ICD codes, trade tickets)
- Evaluate calibration — reliability diagrams + Brier score — for every classifier feeding a clinical or financial decision
- For ESI work: explicitly compare your fine-tuned decoder against a Clinical ModernBERT baseline; document why the larger model's latency is acceptable
Next 12 Months: Strategic
- Invest in domain encoders, not from-scratch domain LLMs. BloombergGPT-class spend is rarely justified. ModernBERT-class continued pretraining on UAE clinical corpora is. For Arabic/Emirati medical NLP specifically, continued pretraining on local EHR text will outperform any general LLM at the relevant tasks at a fraction of the cost.
- Build the hybrid pipeline as a reusable platform: encoder edge classifier → seq2seq or decoder generator (with constrained decoding) → encoder verifier. This pattern applies to clinical NLP, financial NLP, and every regulated NLP use case. Build it once; configure it per domain.
- Watch these inflection points: (a) when open-weights models clear BFCL multi-turn thresholds — that changes agentic deployment risk profiles; (b) when frontier LLM inference drops 10× in cost — that shifts the encoder/decoder cost-benefit calculation; (c) when a domain LLM demonstrates encoder-equivalent calibration — that erodes the encoder's regulatory advantage.
Honest Caveats
This field moves fast. Architecture guidance that was correct in 2024 is partially wrong in 2026, and some of what I've written here will be wrong by 2027. A few things to hold loosely:
- Calibration of LLM outputs is active research. Don't assume decoder log-probs are calibrated class probabilities without explicit validation on your domain.
- Hallucination rates remain non-trivial. Multiple 2024–2025 papers document persistent rates even in frontier models on clinical and financial summarization. Human-in-the-loop is not optional for safety-critical deployment.
- Regulatory variance is real. HIPAA, GDPR, UAE DHA/DoH rules, SR-11-7, EU AI Act, MiFID II all impose architecture-level constraints that may force encoder choices even when a decoder is technically superior. Know your jurisdiction.
- Domain pretraining trade-offs. PubMedBERT-style from-scratch pretraining beats continued pretraining when in-domain text is abundant — but only if your tasks live entirely in that domain. Mixed-domain tasks often favor general models with light adaptation.
Key Sources
Foundations
- Attention Is All You Need — Vaswani et al., 2017
- BERT — Devlin et al., 2018
- DeBERTa — He et al. / DeBERTa-v3
- ModernBERT — Warner et al., Dec 2024
- T5 — Raffel et al. / FLAN-T5 — Chung et al.
- PEGASUS — Zhang et al. / BART — Lewis et al.
Decoder-Only LLMs
- GPT-3 — Brown et al. / GPT-4 Technical Report
- Constitutional AI (Claude) — Bai et al.
- Llama 3 Herd — Dubey et al.
- Qwen2.5 Technical Report
- Mistral 7B — Jiang et al.
HealthIT Clinical NLP
- BioBERT — Lee et al.
- ClinicalBERT — Huang et al.
- PubMedBERT / BiomedBERT — Gu et al.
- Clinical ModernBERT / BioClinical ModernBERT
- Med-PaLM 2 — Nature Medicine 2024
- TrialGPT — Nature Communications 2024
- Medical Hallucination Taxonomy — medRxiv 2025